Podcast: Play in new window | Download (Duration: 32:49 — 22.8MB)
Subscribe: Apple Podcasts | Spotify | RSS | More
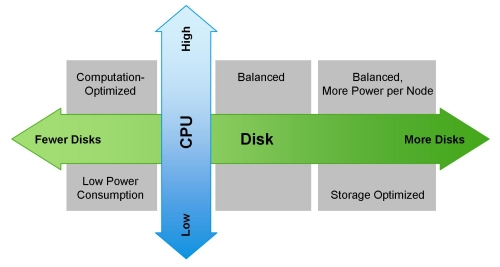
In this continuation of our Hadoop Sizing series we started last September, we move on from sizing your cluster to sizing the individual server chassis or virtual machines in your cluster. We did not finish the entire story just yet, concentrating mainly on the storage component. The final part 3 where we round off the subject with sizing your compute and network resources is planned to be published in the next topic episode. Continue reading “Episode 72 – Hadoop sizing part 2: Storage sizing”

