In this episode, Global Black Belt and Technical Architect in Big Data and Advanced Analytics Team at Microsoft, Alex Zeltov, is our guest and he explains the in’s and out’s of MLOps though various tools like mlflow and kubeflow

Podcast: Play in new window | Download (Duration: 44:37 — 30.9MB)
Subscribe: Apple Podcasts | Spotify | RSS | More
In this second part, we go into more depth on the practical consequences of implementing MLOps and the various tools that are available.
We also go on a bit of a tangent discussing why traditional enterprises are still having a hard time to look at machine learning models as something that requires and benefits from things like model management, version control and periodic updating of models.
For more from Alex on MLOps and mlflow, check out his presentation at the Washington DC DataWorks Summit a couple, of weeks ago. The slides are now available on SlideShare and the video is available on YouTube:
MLOps
Just like DataOps follows on to DevOps, one may say that MLOps continues after DataOps. While there is a wikipedia page on the subject, there is not that much “prior art” available just yet.
The main advantages that MLOps can deliver, according to Alex, are a much improved move to production of trained algorithmes, even allowing for CI/CD, and a more structured approach to training models where multiple data scientists can work together to achieve better results.
mlflow
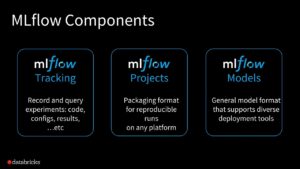 One of the main tools emerging at the moment is the DataBricks backed mlflow project. Though not an Apache project, it has been open sourced under the Apache License now and shows much promise.
One of the main tools emerging at the moment is the DataBricks backed mlflow project. Though not an Apache project, it has been open sourced under the Apache License now and shows much promise.
In the episode, Alex explains how mlflow integrates with your data science notebooks to allow for reliable model management with minimal disruption.
Kubeflow
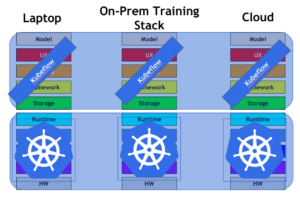
The second contender to reach for the MLOps crown is Kubeflow.
Even though less mature than mlflow, it is backed by the very popular Kubernetes framework and that brings a large community together working on this project.
Please use the Contact Form on this blog or our twitter feed to send us your questions, or to suggest future episode topics you would like us to cover.