Podcast: Play in new window | Download (Duration: 34:58 — 24.3MB)
Subscribe: Apple Podcasts | Spotify | RSS | More
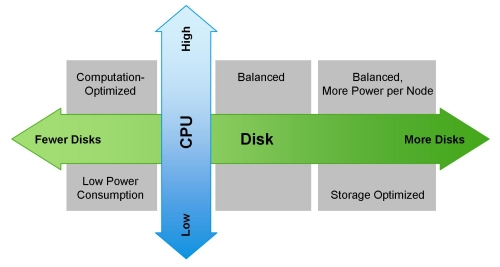
In this edition of the Roaring News series, we talk about delivering business value and how to build an analytics team. For the Machine learning aficionados, we cover the top ML algorithms and we round off with an article on sizing a Apache Flink cluster, which fits nicely with the previous and next episode!